Now we have seen the basic ideas of monadicity, and Beck’s monadicity theorem, it’s time to look at an important application. Although the result in question belongs to the area of topos theory, to avoid pulling in too much additional theory we will consider a concrete example, and then sketch how this extends to the abstract setting.
Subsets and the contravariant powerset
For our motivating example, we are going to consider the category 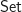

which we shall denote 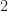



and given any subset 

In this way, we can go back and forth between subsets and what are known as their characteristic functions. For a fixed set 

extends to a functor. For 


It is straightforward to check that this satisfies the functor axioms, so we have a functor:

sometimes referred to as the contravariant powerset functor. This functor has a left adjoint, which we shall also denote

Notice the only difference here is whether we choose to put the “op” on the domain or codomain. Establishing that these two functors form an adjunction is straightforward, as we have natural bijections between:
- Functions
in
- Functions
in
- Functions
in
- Functions
in
- Functions
in
We have seen a more abstract version of this proof before, as this is a special case of the adjunction that induces the continuation monad, in this case for the endofunctor:

The perhaps surprising observation is that the functor
is monadic, meaning the Eilenberg-Moore category of 
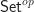
Generalising
At first glance, the argument above looks very specific to the category of sets and functions. Fortunately, there is a very large class of categories that look sufficiently like the category of sets to carry out this argument in the abstract.
As a first step, we look at the important role of the set 




A subobject classifier is a categorical abstraction of the correspondence between subsets (subobjects) and characteristic morphisms. Writing 
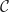
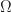

There are several equivalent definitions of subobject classifiers. The typical statement involves a generic subobject and a pullback condition, but as we won’t delve into the details, the statement above emphasises the relationship between subobjects and classifying morphisms.
Example: The set
The class of categories that look sufficiently like the category of sets for our purposes are known as toposes. A topos is a finitely complete, Cartesian closed category with a subobject classifier. (There are almost as many equivalent definitions of a topos as there are books on the subject, depending on the perspective the author wishes to emphasize. We choose this one as it is reasonably straightforward.). There are many examples of toposes that crop up in mathematical practice.
Example: The category
Example: For any small category 
For a topos

It is a non-trivial observation that this functor is monadic. As a concrete argument is no longer possible, this is typically established using a monadicity theorem. Interested readers that are prepared for a bit of topos theory can find the details in any good book on topos theory. Slightly confusingly, topos theorists also refer to this result as the (topos theoretic) monadicity theorem.
This result has an immediate pay-off. As a topos is finitely complete, 
Conclusion
Our discussion of topos theory has been deliberately somewhat sketchy, to avoid pulling in too many technical details. Topos theory is a vast subject, with connections to many parts of mathematics, and would probably warrant a blog of its own.
Further reading: Readers interested in filling in some of the topos theoretic technical details could look at one of the standard sources, such as volume 1 of Johnstone’s “Sketches of an Elephant”, Moerdijk and MacLane’s “Sheaves in Geometry and Logic” or volume 3 of Borceux’s “Handbook of Categorical Algebra”.
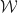 , a monad in
, a monad in  , a
, a 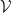 –
– is a generalisation of ordinary categories with:
is a generalisation of ordinary categories with: .
.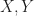 , a hom object
, a hom object  .
. .
.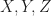 , a composition
, a composition  .
.![([\mathcal{C}, \mathcal{C}], \circ, \mathsf{Id}_{\mathcal{C}})](https://s0.wp.com/latex.php?latex=%28%5B%5Cmathcal%7BC%7D%2C+%5Cmathcal%7BC%7D%5D%2C+%5Ccirc%2C+%5Cmathsf%7BId%7D_%7B%5Cmathcal%7BC%7D%7D%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002) . Using the fundamental meme of monad theory, that a monad is just a monoid in the category of endofunctors, we can deduce that monads on
. Using the fundamental meme of monad theory, that a monad is just a monoid in the category of endofunctors, we can deduce that monads on ![[\mathcal{C},\mathcal{C}]](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BC%7D%2C%5Cmathcal%7BC%7D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) -enriched categories. This claim works equally well if we consider monads in an arbitrary bicategory.
-enriched categories. This claim works equally well if we consider monads in an arbitrary bicategory. . Applying the observation above, the following all describe the same data:
. Applying the observation above, the following all describe the same data: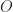 .
. -enriched category.
-enriched category. -enriched category.
-enriched category. in
in  .
. .
. .
. .
.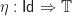 .
. .
. is a monad. That is:
is a monad. That is: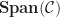 . Now applying our previous observation, the following all describe the same data:
. Now applying our previous observation, the following all describe the same data: ,
,  is given as the coequalizer of a parallel pair of morphisms between free algebras in
is given as the coequalizer of a parallel pair of morphisms between free algebras in  . In this case, we say that
. In this case, we say that  is a regular quotient of free algebras. Notice we are not making any any assumptions about the base category
is a regular quotient of free algebras. Notice we are not making any any assumptions about the base category 

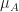 is an algebra morphism is equivalent to the Eilenberg-Moore algebra multiplication axiom. That
is an algebra morphism is equivalent to the Eilenberg-Moore algebra multiplication axiom. That  is an algebra morphism is simply naturality of the monad multiplication.
is an algebra morphism is simply naturality of the monad multiplication. , we note that there is an algebra morphism in the opposite direction:
, we note that there is an algebra morphism in the opposite direction:


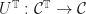 , yielding a parallel pair.
, yielding a parallel pair.

 . The obvious choice is to consider
. The obvious choice is to consider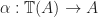

 .
. .
.

 .
.
 -contractible pair.
-contractible pair.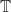 and
and  . As contractible coequalizers are absolute colimits, we can apply this result to lift the coequalizer to the Eilenberg-Moore category.
. As contractible coequalizers are absolute colimits, we can apply this result to lift the coequalizer to the Eilenberg-Moore category. is in fact an algebra morphism of type:
is in fact an algebra morphism of type:

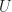 -contractible coequalizers in the statement of
-contractible coequalizers in the statement of  is monadic if and only if the following three conditions hold:
is monadic if and only if the following three conditions hold: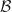 has coequalizers of reflexive
has coequalizers of reflexive  ,
, 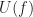 is an isomorphism implies
is an isomorphism implies  is isomorphic to
is isomorphic to  then
then  .
. 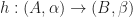 , then in
, then in  .
. such that
such that and
and 
 is an algebra morphism of type
is an algebra morphism of type  . This is a straightforward calculation:
. This is a straightforward calculation: .
.
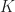 is the comparison functor, if
is the comparison functor, if  be the category of posets and monotone maps, and
be the category of posets and monotone maps, and  the obvious forgetful functor. This functor has a left adjoint, and so satisfies the first condition of the monadicity theorem. Now consider the two element posets:
the obvious forgetful functor. This functor has a left adjoint, and so satisfies the first condition of the monadicity theorem. Now consider the two element posets: with the discrete partial order.
with the discrete partial order.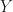 , with underlying set
, with underlying set  with the least partial order such that
with the least partial order such that  .
.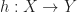 with
with  and
and  . This morphism has no inverse monotone map. On the other hand, the underlying function
. This morphism has no inverse monotone map. On the other hand, the underlying function  has an obvious inverse in
has an obvious inverse in  taking a small category to its set of objects is not monadic.
taking a small category to its set of objects is not monadic. 
 such that
such that and
and  .
. and
and  .
. .
. .
.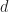 coequalizes the parallel pair, that is
coequalizes the parallel pair, that is  .
. , that is
, that is  , that is
, that is  .
. .
.  has a contractible coequalizer. Notice this terminology is slightly misleading, we are requiring a contractible coequalizer, not just a contractible pair.
has a contractible coequalizer. Notice this terminology is slightly misleading, we are requiring a contractible coequalizer, not just a contractible pair. is monadic, as
is monadic, as such that
such that .
. .
.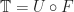


 and
and  .
.
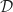 if for every diagram
if for every diagram
 exists, with limit cone:
exists, with limit cone:
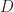 -cone
-cone
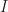

 is the limit of the diagram
is the limit of the diagram 

 exists, with limit cone:
exists, with limit cone:
 is an algebra homomorphism:
is an algebra homomorphism:
 completely determines what
completely determines what 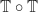 . Again, we get very nice behaviour, but for a slightly strange looking restricted class of colimits. The proof is similar to that for limits, exploiting the universal property of colimits in the base category to find a unique algebra structure map such that the cocone morphisms in the base category are algebra morphisms. The additional preservation assumptions are used to get colimits of the required shape to complete the argument.
. Again, we get very nice behaviour, but for a slightly strange looking restricted class of colimits. The proof is similar to that for limits, exploiting the universal property of colimits in the base category to find a unique algebra structure map such that the cocone morphisms in the base category are algebra morphisms. The additional preservation assumptions are used to get colimits of the required shape to complete the argument. -relative monad
-relative monad  , an Eilenberg-Moore algebra consists of:
, an Eilenberg-Moore algebra consists of: , a morphism
, a morphism  .
. .
. and
and  ,
,  .
. is a
is a 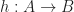 such that for every
such that for every  :
:
 , the Eilenberg-Moore category.
, the Eilenberg-Moore category. , and a unit, denoted
, and a unit, denoted  , satisfying the following three equations:
, satisfying the following three equations: .
. .
. .
.
 , non of the following terms can be proved equal:
, non of the following terms can be proved equal:
 including the finite sets into the infinite sets, relating the finite and infinite aspects at play. For any finite set
including the finite sets into the infinite sets, relating the finite and infinite aspects at play. For any finite set  to be the equivalence class of terms over
to be the equivalence class of terms over 
 . Finally, we can think of a function
. Finally, we can think of a function

 -relative monad
-relative monad  telling us how the binary operation behaves.
telling us how the binary operation behaves. specifying the value of the unit.
specifying the value of the unit.
 , we can evaluate this term to an element of the carrier using the specified multiplication operation and unit constant, if we are given an element in the carrier for each of the variables. In fact, we should get the same value for any term provably equal to this one such as
, we can evaluate this term to an element of the carrier using the specified multiplication operation and unit constant, if we are given an element in the carrier for each of the variables. In fact, we should get the same value for any term provably equal to this one such as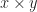

 term from a
term from a  tells us how to evaluate such terms, with the valuation
tells us how to evaluate such terms, with the valuation  specifying the values of the variables.
specifying the values of the variables. .
. ,
, has universe
has universe  :
:
 .
. is
is  assume we have a
assume we have a  . The Kleisli category
. The Kleisli category  has:
has: in
in  . The identity at
. The identity at  . The composite
. The composite  in the Kleisli category is given by
in the Kleisli category is given by  in
in  is the category with:
is the category with: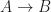 is a binary relation
is a binary relation 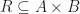 . Composition and identities are the usual thing for binary relations.
. Composition and identities are the usual thing for binary relations.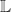 . The Kleisli category has:
. The Kleisli category has: with composition and identities as for the ordinary list monad.
with composition and identities as for the ordinary list monad. . Composition and identities are exactly as in
. Composition and identities are exactly as in  gives the category of non-empty sets and functions between them.
gives the category of non-empty sets and functions between them. gives the category of sets with at least
gives the category of sets with at least  elements, and functions between them.
elements, and functions between them. has Kleisli category equivalent to the Kleisli category of the
has Kleisli category equivalent to the Kleisli category of the  .
. has Kleisli category equivalent to the Kleisli category of the
has Kleisli category equivalent to the Kleisli category of the  -relative monad is the same thing as an ordinary monad. The associated Kleisli construction is also the same as in the case of ordinary monads.
-relative monad is the same thing as an ordinary monad. The associated Kleisli construction is also the same as in the case of ordinary monads. , we have the following functors:
, we have the following functors: , with
, with  , and
, and  .
. , with
, with  and
and  .
. is a
is a  , and that this adjunction induces the relative monad
, and that this adjunction induces the relative monad  and
and  is a functor
is a functor  commuting with the left and right adjoints in the obvious way. The Kleisli adjunction is initial in this category. For another resolution with left adjoint
commuting with the left and right adjoints in the obvious way. The Kleisli adjunction is initial in this category. For another resolution with left adjoint 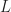 , the unique Kleisli comparison functor is given on objects by
, the unique Kleisli comparison functor is given on objects by  and on morphisms
and on morphisms  is the transpose of
is the transpose of 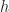 under the codomain adjunction. As taking transposes is a bijection, this functor is full and faithful.
under the codomain adjunction. As taking transposes is a bijection, this functor is full and faithful. :
: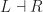 and
and  , we have natural isomorphisms:
, we have natural isomorphisms:
 \cong \int_C \mathcal{D}(F(C),R(C)) \cong \int_C \mathcal{D}(F(C),R'(C)) \cong [\mathcal{C},\mathcal{D}](F,R')](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BC%7D%2C%5Cmathcal%7BD%7D%5D%28F%2CR%29+%5Ccong+%5Cint_C+%5Cmathcal%7BD%7D%28F%28C%29%2CR%28C%29%29+%5Ccong+%5Cint_C+%5Cmathcal%7BD%7D%28F%28C%29%2CR%27%28C%29%29+%5Ccong+%5B%5Cmathcal%7BC%7D%2C%5Cmathcal%7BD%7D%5D%28F%2CR%27%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 \cong \int_C \mathcal{C}(F(C),G(C))](https://s0.wp.com/latex.php?latex=%5BC%2CD%5D%28F%2CG%29+%5Ccong+%5Cint_C+%5Cmathcal%7BC%7D%28F%28C%29%2CG%28C%29%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 ,
, are left
are left 
 \cong \int_B \mathcal{C}(L(B),F(B)) \cong \int_B \mathcal{C}(L'(B),F(B)) \cong [\mathcal{B},\mathcal{C}](L',F)](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BB%7D%2C%5Cmathcal%7BC%7D%5D%28L%2CF%29+%5Ccong+%5Cint_B+%5Cmathcal%7BC%7D%28L%28B%29%2CF%28B%29%29+%5Ccong+%5Cint_B+%5Cmathcal%7BC%7D%28L%27%28B%29%2CF%28B%29%29+%5Ccong+%5B%5Cmathcal%7BB%7D%2C%5Cmathcal%7BC%7D%5D%28L%27%2CF%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002) ,
, . So far, so straightforward.
. So far, so straightforward. , so we have natural isomorphisms:
, so we have natural isomorphisms:
 \cong \int_C \mathcal{D}(F(C),R(C))](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BC%7D%2C%5Cmathcal%7BD%7D%5D%28F%2CR%29+%5Ccong+%5Cint_C+%5Cmathcal%7BD%7D%28F%28C%29%2CR%28C%29%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002) ,
,![\mathcal{D} \rightarrow [\mathcal{B}^{op},\mathsf{Set}]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BD%7D+%5Crightarrow+%5B%5Cmathcal%7BB%7D%5E%7Bop%7D%2C%5Cmathsf%7BSet%7D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
,D), \mathcal{D}(J(-),D'))](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BD%7D%28D%2CD%27%29+%5Ccong+%5B%5Cmathcal%7BB%7D%5E%7Bop%7D%2C%5Cmathsf%7BSet%7D%5D%28%5Cmathcal%7BD%7D%28J%28-%29%2CD%29%2C+%5Cmathcal%7BD%7D%28J%28-%29%2CD%27%29%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 &\cong \int_C \mathcal{D}(F(C),R(C)) \\ &\cong \int_C [\mathcal{B}^{op},\mathsf{Set}](\mathcal{D}(J(-),F(C)), \mathcal{D}(J(-),R(C))) \\ &\cong \int_C \int_B \mathsf{Set}(\mathcal{D}(J(B),F(C)), \mathcal{D}(J(B),R(C))) \\ &\cong \int_C \int_B \mathsf{Set}(\mathcal{D}(J(B),F(C)), \mathcal{D}(J(B),R'(C))) \\ &\cong \int_C [\mathcal{B}^{op},\mathsf{Set}](\mathcal{D}(J(-),F(C)), \mathcal{D}(J(-),R'(C))) \\ &\cong \int_C \mathcal{D}(F(C),R'(C)) \\ &\cong [\mathcal{C},\mathcal{D}] (F,R') \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5B%5Cmathcal%7BC%7D%2C%5Cmathcal%7BD%7D%5D%28F%2CR%29+%26%5Ccong+%5Cint_C+%5Cmathcal%7BD%7D%28F%28C%29%2CR%28C%29%29++%5C%5C+%26%5Ccong+%5Cint_C+%5B%5Cmathcal%7BB%7D%5E%7Bop%7D%2C%5Cmathsf%7BSet%7D%5D%28%5Cmathcal%7BD%7D%28J%28-%29%2CF%28C%29%29%2C+%5Cmathcal%7BD%7D%28J%28-%29%2CR%28C%29%29%29+%5C%5C+%26%5Ccong+%5Cint_C+%5Cint_B+%5Cmathsf%7BSet%7D%28%5Cmathcal%7BD%7D%28J%28B%29%2CF%28C%29%29%2C+%5Cmathcal%7BD%7D%28J%28B%29%2CR%28C%29%29%29+%5C%5C+%26%5Ccong+%5Cint_C+%5Cint_B+%5Cmathsf%7BSet%7D%28%5Cmathcal%7BD%7D%28J%28B%29%2CF%28C%29%29%2C+%5Cmathcal%7BD%7D%28J%28B%29%2CR%27%28C%29%29%29+%5C%5C+%26%5Ccong+%5Cint_C+%5B%5Cmathcal%7BB%7D%5E%7Bop%7D%2C%5Cmathsf%7BSet%7D%5D%28%5Cmathcal%7BD%7D%28J%28-%29%2CF%28C%29%29%2C+%5Cmathcal%7BD%7D%28J%28-%29%2CR%27%28C%29%29%29+%5C%5C+%26%5Ccong+%5Cint_C+%5Cmathcal%7BD%7D%28F%28C%29%2CR%27%28C%29%29+%5C%5C+%26%5Ccong+%5B%5Cmathcal%7BC%7D%2C%5Cmathcal%7BD%7D%5D+%28F%2CR%27%29+%5Cend%7Baligned%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 .
.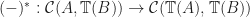 ,
,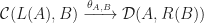

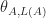 has type
has type
 .
.
 is the map that applies the functor
is the map that applies the functor  .
.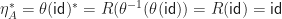 .
.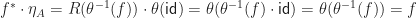 ,
, in the only non-trivial step.
in the only non-trivial step. 
 as the image of the identity under a map of type:
as the image of the identity under a map of type:
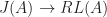 . This suggests we require a natural isomorphism of type:
. This suggests we require a natural isomorphism of type: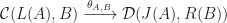
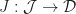 ,
,  and
and  . If we have such an isomorphism, we can follow an almost identical recipe to before to form a
. If we have such an isomorphism, we can follow an almost identical recipe to before to form a  .
. .
. .
.

 is full and faithful if and only if
is full and faithful if and only if 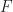 -relative left adjoint, as that is the case when we have a natural isomorphism:
-relative left adjoint, as that is the case when we have a natural isomorphism: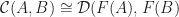
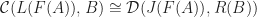
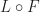 is
is 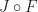 -relative left adjoint to
-relative left adjoint to 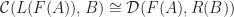
 , but no counit. On the other hand, right
, but no counit. On the other hand, right  , but no unit.
, but no unit.