In many previous posts, we have discussed connections between monads and universal algebra. So far, we have seen that given a presentation  of an algebraic theory in terms of set of operations
of an algebraic theory in terms of set of operations  , and equations
, and equations 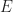 , there is a corresponding monad
, there is a corresponding monad 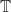 such that:
such that:
- The Eilenberg-Moore algebras of the monad are the algebras described by the chosen presentation.
- The Kleisli category is the full subcategory of free algebras.
Many other aspects of monad theory can then be stood from this algebraic perspective.
Every monad arising from a presentation in terms of operations and equations is finitary. This is a technical condition saying that certain colimits are preserved by the monad endofunctor, but we will not dwell on the precise details. Intuitively, the idea is that the functor is completely defined by its action on finite objects. The key point is that there is a correspondence between algebraic presentations and finitary monads, for which the categories of algebras coincide. It is essential that the categories of models agree for this relationship to be algebraically meaningful. Note this is not a bijection, as a given finitary monad will have infinitely many potential presentations in terms of operations and equations.
In this post, we will see a third perspective on describing algebraic structures, Lawvere theories. These sit somewhere between conventional universal algebra and monads in their level of abstraction. As with any mathematical phenomenon, each new perspective deepens our understanding, and emphasises new features and intuitions.
The Idea of Lawvere Theories
To be concrete, lets consider what we need to do to describe a monoid. The general situation for different algebraic structures will follow in the same way.
Typically, we first pick out an underlying set  , and two functions:
, and two functions:
- A zero argument function, or constant, for the unit element. We can identity this as a function
 .
.
- A two argument function, or binary operation, for the monoid multiplication. We can identify this with a function
 .
.
Of course, once we have these functions, we can build further ones by combining them together. For example
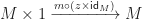
Which informally we can think of as corresponding to a term  . Of course, by one of the monoid unit axioms, we require that this composite is equal to
. Of course, by one of the monoid unit axioms, we require that this composite is equal to
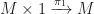
which we can think of as corresponding to a variable  . So in this way of describing a monoid, we:
. So in this way of describing a monoid, we:
- Pick out some basic operations, which are maps of the form
 .
.
- Build lots of other operations by composing the basic operations together, using category composition, and the properties of products.
- Require that certain of the operations are equal.
We note some issues with this naive plan. Firstly, where did the basic operations come from, and why do we distinguish them from the other operations? This bias towards certain operations seems categorically unnatural, and raises the ugly question of whether any further mathematical results we derive might be dependent on our choice of presentation. Secondly, a small but annoying detail. It was a pain that  was only isomorphic, and not equal to when we built our composite terms. If we build up more complicated composites involving higher Cartesian powers, we will spend a lot of time bookkeeping how to bracket expressions like:
was only isomorphic, and not equal to when we built our composite terms. If we build up more complicated composites involving higher Cartesian powers, we will spend a lot of time bookkeeping how to bracket expressions like:

for no practical benefit. So putting all this together, it would be convenient if we could describe the theory of monoids as a category with:
- Objects the natural numbers, corresponding to the number of arguments of our operations.
- (Strict) finite products are given by adding the required arities together
 .
.
- Intuitively, we consider an operation of arity
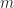 to be a morphism of type
to be a morphism of type 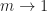 . For example, a binary operation is a morphism
. For example, a binary operation is a morphism  and a constant is a morphism
and a constant is a morphism  . Notice that, unlike the common convention, in this case
. Notice that, unlike the common convention, in this case  is the terminal object.
is the terminal object.
- A family of
 such operations is a morphism of type
such operations is a morphism of type  . This is automatic from universal property of the assumed strict finite products.
. This is automatic from universal property of the assumed strict finite products.
- A diagram commutes in our category if and only if the corresponding operations should be equal in the theory of monoids.
In fact, it is technical important to add a little bit more structure. If we consider the category of sets, and take the full subcategory with objects

this category clearly has finite coproducts, given by:

If we identify the objects of this category with the natural numbers, via:

this yields a category with finite coproducts 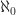 , and therefore a category with finite products
, and therefore a category with finite products  .
.
Moving away from the special case of monoids, we then define a Lawvere theory to be a category  with strict finite products, with an identity on objects strict finite product preserving functor
with strict finite products, with an identity on objects strict finite product preserving functor 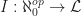 . The category can be interpreted as encoding the operations and equations of the theory. We shall return to the interpretation of the inclusion
. The category can be interpreted as encoding the operations and equations of the theory. We shall return to the interpretation of the inclusion 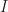 later. A morphism of Lawvere theories
later. A morphism of Lawvere theories 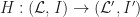 is a finite product preserving functor
is a finite product preserving functor  such that
such that  .
.
What we really wanted to do was describe a class of algebraic structures, using our theory. A model of a Lawvere theory in a category with finite products 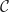 is a finite product preserving functor
is a finite product preserving functor
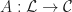
and a homorphism of models is a natural transformation between them. For conventional algebraic structures, we take 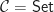 . Note we don’t require that the models interact appropriately with the product structure, as in fact this is automatic. The category of models of a Lawvere theory and their homomorphisms is denoted
. Note we don’t require that the models interact appropriately with the product structure, as in fact this is automatic. The category of models of a Lawvere theory and their homomorphisms is denoted

This approach of identifying structures with functors from a suitably structured category is known as functorial semantics. Notice the difference with monads as a categorical tool for describing algebraic structures. The Eilenberg-Moore category of a monad captures algebraic structures on a fixed base category, whereas we can straightforwardly considering models of Lawvere theories in any category with finite products. There is a forgetful functor given by evaluation at the object  :
:
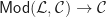
In many cases, for example if is locally presentable, this functor will have a left adjoint, and will therefore induce a monad on . So a single Lawvere theory induces monads on many different base categories.
If we have two Lawvere theories such that we have equivalence:

then there is an isomorphism  in the category of Lawvere theories. So there is a very tight correspondence between Lawvere theories and the category of models that they describe.
in the category of Lawvere theories. So there is a very tight correspondence between Lawvere theories and the category of models that they describe.
How to build a Lawvere – take one
So how do we build a Lawvere theory? One approach is to start with a presentation  . We then form a category with:
. We then form a category with:
- Object the natural numbers
- Morphisms
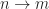 are m-tuples of terms in variables, quotiented by provable equality in equational logic, with respect to the equations of our presentation.
are m-tuples of terms in variables, quotiented by provable equality in equational logic, with respect to the equations of our presentation.
- The product projection onto the ith component of a product corresponds to the term for the ith variable.
- Identity morphisms are (necessarily) the tuples of projection morphisms.
- Composition is given by substitution of terms.
- The inclusion morphism picks out the projection morphism in .
So we see the intuition for the inclusion is that it picks out the trivial terms corresponding to bare variables within the broader collection of operations.
Example: We can build a Lawvere theory for monoids from the usual presentation in terms of a unit and multiplication operation, and unitality and associativity axioms. The category 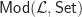 is then equivalent to the usual category of monoids.
is then equivalent to the usual category of monoids.
Note is important that we do not require models of a Lawvere theory strictly preserves product structure. For the usual products in 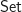 , if we did this, the category of models for the Lawvere theory of monoids would be empty!
, if we did this, the category of models for the Lawvere theory of monoids would be empty!
How to build a Lawvere Theory – take two
Instead of starting with a presentation in terms of operations and equations, what if we were given a finitary monad? Can we construct a Lawvere theory directly from this data?
The structure of a Lawvere theory in terms of equivalence classes of terms composed by substitution sounds suspiciously like the algebraic perspective on the Kleisli category of a monad. In fact, the two are very similar, up to some cosmetic details. For a finitary -monad , we can construct a Lawvere theory  as follows:
as follows:
- Form the Kleisli category
 .
.
- Restrict to the full subcategory of objects
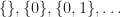 , and rename the objects to natural numbers in a similar way to the section above.
, and rename the objects to natural numbers in a similar way to the section above.
- Take the opposite category.
Tersely, we say the required Lawvere theory is the opposite of (the skeleton of) the full subcategory of finitely generated free algebras. As we would hope, we have an equivalence between  and , so the categories of models coincide.
and , so the categories of models coincide.
Monads to Lawvere Theories
Given a Lawvere theory , we would like to go in the other direction, and construct a corresponding finitary monad. This can be done by taking a coend:

If this is unfamilar, the idea is that we can construct the required monad as a certain categorical colimit. Intuitively, we form the collection of equivalence classes of terms, identifying product structure where appropriate.
Again, the categories of Eilenberg-Moore algebras and models of the Lawvere theory in agree up to equivalence.
In fact, the connection between Lawvere theories and finitary monads is about as strong as we might hope. The category of Lawvere theories is equivalent to the category of finitary monads on . The presence of the inclusion morphism in the definition of a Lawvere theory ensures that this equivalence goes through correctly.
Conclusion
Lawvere theories give a presentation independent formulation of algebra. They have several strengths:
- They are relatively close in form to concepts from conventional universal algebra. In particular, they can be seen as an abstraction of the notion of clone.
- Unlike monads, a single object can describe models taken in different categories. For example, we can take models of the Lawvere theory of monoids in sets, posets, topological spaces and so on.
- Certain operations for combining theories are more natural from the perspective of Lawvere theories, rather than that of finitary monads.
- They are algebraic by construction. By comparison, monads include structures such as the continuation monad, which don’t have a clear interpretation in terms of universal algebra.
There are many generalisations of Lawvere theories, for example to incorporate operations of larger aritites, or enrichments of the base category. These typically come with a correspondence to a natural class of monads, providing a different perspective to work with. The functorial semantics of Lawvere theories also suggests other structures, such as PROs and PROPs, which move us further away from convention algebra to structures potentially having multiple outputs as well as inputs.
One intriguing question is what is the equivalent of Lawvere theories for comonads. At this point there does not seem to be a satisfactory answer, as highlighted in the paper “Category Theoretic Understandings of Universal Algebra and its dual: monads and Lawvere theories, comonads and ?” This example highlight how comonad theory cannot always be seen as routinely “flipping monad theory upside down”, and sometimes a routine application of duality isn’t enough.
Further reading: An excellent source for background is the book “Algebraic Theories” by Adamek, Rosicky and Vitale. Also useful for background is Hyland and Power’s “The Category Theoretic Understanding of Universal Algebra: Lawvere Theories and Monads”. Power has developed much of the theory generalising Lawvere theories in various ways, and applying them in computer science.

![[\mathcal{C},\mathcal{C}]](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BC%7D%2C%5Cmathcal%7BC%7D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

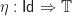


![[\mathcal{C}, \mathcal{D}]](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BC%7D%2C+%5Cmathcal%7BD%7D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
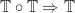
.
-indexed family of unit morphisms
.
, indexed by pairs of
.
.
.

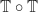
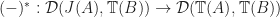
.
, indexed by pairs of
with action
.
.
are natural in both variables. That is:
.

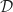


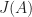
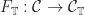

 ,
, 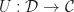 .
. as above, where the category
as above, where the category  is rarely equivalent to the Kleisli category. (Although there are examples where this is the case).
is rarely equivalent to the Kleisli category. (Although there are examples where this is the case).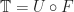 , there is a
, there is a 
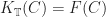
 :
: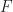 is bijective on objects.
is bijective on objects.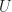 , inducing monad
, inducing monad 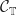 if
if 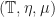 on some 0-cell
on some 0-cell  , and a 1-cell
, and a 1-cell ,
,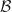 ? Obviously this is a rather imprecise specification, lets explore some possibilities.
? Obviously this is a rather imprecise specification, lets explore some possibilities.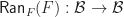 ,
, along
along  .
.
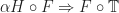 and
and 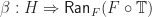 :
: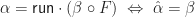
 to simplify notation, we find that:
to simplify notation, we find that: .
. .
. , such that the right extension
, such that the right extension 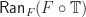 exists, there is a canonical monad induced on
exists, there is a canonical monad induced on  , the composite
, the composite  is a monad on
is a monad on  , there is a bijective correspondence between:
, there is a bijective correspondence between: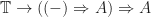 with codomain the
with codomain the 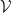 , a
, a  an object in
an object in  has objects preorders, and morphisms monotone maps. This category has products, and so can be seen as a monoidal category with respect to this structure. A
has objects preorders, and morphisms monotone maps. This category has products, and so can be seen as a monoidal category with respect to this structure. A  is a preorder.
is a preorder. and
and  implies that
implies that  .
. the exponential
the exponential  . This is usually phrased as
. This is usually phrased as  in
in  by setting
by setting  , and defining the composition morphism of type
, and defining the composition morphism of type
 is the symmetry, and
is the symmetry, and  is the composition morphism in
is the composition morphism in 
 . We then get a generalisation of the previous result, that for any other
. We then get a generalisation of the previous result, that for any other 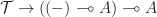 .
.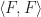 for this codensity monad.
for this codensity monad.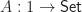 that picks out that object. This will induce a monad on
that picks out that object. This will induce a monad on 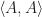 is the continuation monad induced by
is the continuation monad induced by  , with codomain the codensity monad induced by the functor
, with codomain the codensity monad induced by the functor 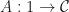 .
. be a 2-category, and
be a 2-category, and 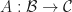 , there is a bijective correspondence between:
, there is a bijective correspondence between: with codomain the codensity monad induced by
with codomain the codensity monad induced by  . Working at this level of abstraction will provide results that apply in other settings, for example monads in the sense of enriched category theory. Even if all you care about is ordinary monads, this perspective forces us towards a universal property characterisation of the usual Eilenberg-Moore category, rather than our previous focus on an explicit construction.
. Working at this level of abstraction will provide results that apply in other settings, for example monads in the sense of enriched category theory. Even if all you care about is ordinary monads, this perspective forces us towards a universal property characterisation of the usual Eilenberg-Moore category, rather than our previous focus on an explicit construction.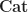 . In particular, 1 and 2-cells can be composed vertically and horizontally just as functors as natural transformations can. For readers aware of such issues, we will be working entirely with strict 2-categories and 2-functors, so there are no distracting coherence isomorphisms to worry about either.
. In particular, 1 and 2-cells can be composed vertically and horizontally just as functors as natural transformations can. For readers aware of such issues, we will be working entirely with strict 2-categories and 2-functors, so there are no distracting coherence isomorphisms to worry about either.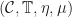 in
in  , we consider the representable 2-functor
, we consider the representable 2-functor
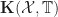
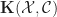 . Concretely, the functor part of this monad acts as:
. Concretely, the functor part of this monad acts as: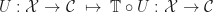
 are
are  and
and 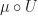 . We can then consider the Eilenberg-Moore category
. We can then consider the Eilenberg-Moore category
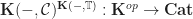

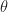 for the 2-isomorphism. We consider the image of the identity 1-cell under
for the 2-isomorphism. We consider the image of the identity 1-cell under 



 for a base of enrichment
for a base of enrichment 
 is the counit of the free / forgetful adjunction for the Eilenberg-Moore category.
is the counit of the free / forgetful adjunction for the Eilenberg-Moore category. such that
such that  in
in  . Sketching the details:
. Sketching the details: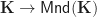
 exactly when there is a 2-natural isomorphism:
exactly when there is a 2-natural isomorphism:

 , where we reverse 1-cells are what are known as Kleisli objects. These appropriately generalise the
, where we reverse 1-cells are what are known as Kleisli objects. These appropriately generalise the 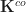 and
and  , where we reverse 2-cells, recover the corresponding theory for comonads, involving what might be called universal left and right co-actions of a comonad.
, where we reverse 2-cells, recover the corresponding theory for comonads, involving what might be called universal left and right co-actions of a comonad. , a left action of
, a left action of 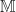 on a functor
on a functor  is a natural transformation:
is a natural transformation:

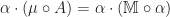
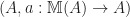
 from the terminal category, which picks out the object
from the terminal category, which picks out the object  is a natural transformation
is a natural transformation 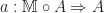 . The axioms for an Eilenberg-Moore algebra exactly correspond to this natural transformation being a left monad action.
. The axioms for an Eilenberg-Moore algebra exactly correspond to this natural transformation being a left monad action. be the non-empty
be the non-empty  let
let 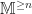 denote the functor forming collections of multisets of at least
denote the functor forming collections of multisets of at least  .
. induces an Eilenberg-Moore algebra:
induces an Eilenberg-Moore algebra:
 be the
be the  be the functor mapping a set to the collection of even length lists of its elements. There is a left monad action:
be the functor mapping a set to the collection of even length lists of its elements. There is a left monad action:

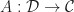

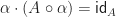

 as before, there are several more methods for systematically construction monad actions. For example:
as before, there are several more methods for systematically construction monad actions. For example:  is a left (and right) monad action.
is a left (and right) monad action. , and
, and  , if
, if 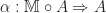 is a left monad action, then so is
is a left monad action, then so is  .
. is a monad action, a
is a monad action, a 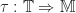 a monad morphism, then
a monad morphism, then  is a left action of
is a left action of 


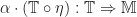

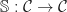 ,
,  , and a functor
, and a functor  :
: , which appropriately preserves the monad structure. Eilenberg-Moore laws were in bijective correspondence with Eilenberg-Moore liftings of
, which appropriately preserves the monad structure. Eilenberg-Moore laws were in bijective correspondence with Eilenberg-Moore liftings of 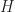 to a functor
to a functor  commuting with the forgetful functors from the Eilenberg-Moore category.
commuting with the forgetful functors from the Eilenberg-Moore category.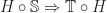 , which appropriately preserve the monad structure. These were in bijection with Kleisli liftings of
, which appropriately preserve the monad structure. These were in bijection with Kleisli liftings of 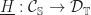 , commuting with the free functors to the Kleisli category.
, commuting with the free functors to the Kleisli category.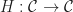
 and
and 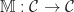 .
.  . Noting that our monad
. Noting that our monad  lives on the same category as
lives on the same category as 


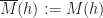
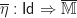 and multiplication
and multiplication  of the lifted monad. The obvious choices are to take:
of the lifted monad. The obvious choices are to take:
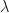 is a Kleisli law. It is also then straightforward to verify that these components form natural transformations, and satisfy the monad axioms, with the details following fairly directly from the same properties in the base category.
is a Kleisli law. It is also then straightforward to verify that these components form natural transformations, and satisfy the monad axioms, with the details following fairly directly from the same properties in the base category.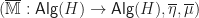 .
. commutes with the monad structure, in that
commutes with the monad structure, in that 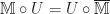 ,
,  and
and  .
. 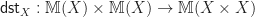

 , the action of the structure map of
, the action of the structure map of  is:
is:
 . Again, we should ask ourselves if it is possible to lift the monad
. Again, we should ask ourselves if it is possible to lift the monad 



 .
.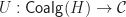 commutes with the monad structure, in that
commutes with the monad structure, in that 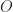 , we consider the endofunctor
, we consider the endofunctor 

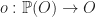 , there is an Eilenberg-Moore law:
, there is an Eilenberg-Moore law:

 will evaluate a set of states pointwise, using the provided Eilenberg-Moore algebra to calculate a suitable output value from the set of available candidates.
will evaluate a set of states pointwise, using the provided Eilenberg-Moore algebra to calculate a suitable output value from the set of available candidates. , it is natural to ask if there is some systematic way to extend
, it is natural to ask if there is some systematic way to extend  to the whole of
to the whole of  ? Of course, when we look for “systematic” or “canonical” ways of doing things in category theory, we are looking for a construction with a universal property.
? Of course, when we look for “systematic” or “canonical” ways of doing things in category theory, we are looking for a construction with a universal property. .
. .
.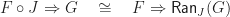 .
. and
and  are respectively known as the left and right Kan extensions of
are respectively known as the left and right Kan extensions of 
 such that for every
such that for every  there exists a unique
there exists a unique  such that
such that  .
.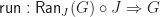 such that for every
such that for every  there exists a unique
there exists a unique  such that
such that  .
. is cocomplete, then
is cocomplete, then ![[\mathcal{D}^{op},\mathsf{Set}] \rightarrow [\mathcal{C}^{op},\mathsf{Set}]](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BD%7D%5E%7Bop%7D%2C%5Cmathsf%7BSet%7D%5D+%5Crightarrow+%5B%5Cmathcal%7BC%7D%5E%7Bop%7D%2C%5Cmathsf%7BSet%7D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![[\mathcal{D}^{op}, \mathsf{Set}]](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BD%7D%5E%7Bop%7D%2C+%5Cmathsf%7BSet%7D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) . These monads are not our main focus for today though.
. These monads are not our main focus for today though. with unit and counit
with unit and counit 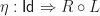 and
and 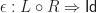 . Then:
. Then: .
. .
.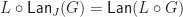 .
. .
.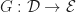 of when we can “lift”
of when we can “lift” 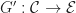 . Notice the difference in direction of travel along
. Notice the difference in direction of travel along  .
. .
. and
and  are respectively the left and right Kan lifts of
are respectively the left and right Kan lifts of 

 .
.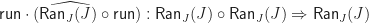
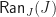 and two natural transformations with the right types to serve as a unit and multiplication for a monad. It turns out that this construction does in fact yield a monad.
and two natural transformations with the right types to serve as a unit and multiplication for a monad. It turns out that this construction does in fact yield a monad.
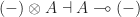
 , the functor
, the functor 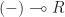 is contravariant. That is, we can view it as having type
is contravariant. That is, we can view it as having type 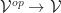 or
or 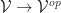 as is convenient to us.
as is convenient to us. in
in 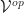
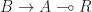 in
in 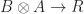 in
in  in
in 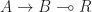
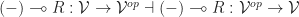

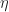 and
and 
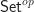 . The multiplication of the monad at
. The multiplication of the monad at 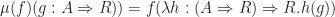
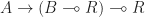 . In the case of
. In the case of 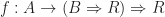
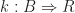 as a continuation. This is how a computation should continue once it has computed a value of type
as a continuation. This is how a computation should continue once it has computed a value of type  , eventually yielding a result of type
, eventually yielding a result of type 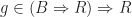 is a computation yielding a
is a computation yielding a  . The functor
. The functor 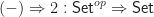 is the contravariant powerset functor. An element
is the contravariant powerset functor. An element  can be seen a characteristic function, mapping elements appearing in a subset to
can be seen a characteristic function, mapping elements appearing in a subset to 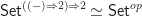
 of complete atomic Boolean algebras and morphisms preserving their joins and meets.
of complete atomic Boolean algebras and morphisms preserving their joins and meets.  known as a subobject classifier, which can be thought of as a collection of truth values. The functor
known as a subobject classifier, which can be thought of as a collection of truth values. The functor  is the analog of the contravariant powerset functor on
is the analog of the contravariant powerset functor on  , we have a wide generalisation of the equivalence above:
, we have a wide generalisation of the equivalence above: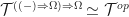
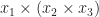
 come from some set
come from some set 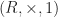 ?
?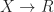 . Secondly, we really only need to specify the value for each equivalence class of terms, so the elements of
. Secondly, we really only need to specify the value for each equivalence class of terms, so the elements of 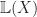 , where
, where 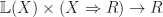
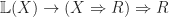
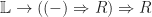
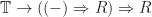
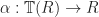 .
.




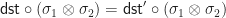
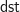 and
and  are the two
are the two 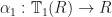 and
and  commute if their corresponding monad morphisms
commute if their corresponding monad morphisms 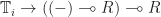 commute as defined above. We then say an algebra is commutative if it commutes with itself.
commute as defined above. We then say an algebra is commutative if it commutes with itself.