Previous posts have focussed quite a lot on general theory. In this post, we are going to examine a couple of specific monads in a fair amount of detail. Both can be seen as dealing with computations parameterised by a notion of external state.
The Reader or Environment Monad
For any set 
- Endofunctor: The monad endofunctor is
.
- Unit: The unit at
maps its input to the constant function
.
- Multiplication: The multiplication acts as follows
.
This monad is called the reader or environment monad. The computational interpretation of this monad is that a function 
Aside: This monad arises via an adjunction involving slice categories. There is an obvious forgetful functor 
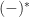
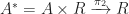
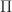

At this level of abstraction, it is not immediately obvious that this adjunction induces the right monad. To at least convince ourselves that the endofunctors agree, we note there is then a series of bijections between hom sets:



We then note that 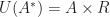



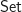
Our main interest is to consider the reader monad from an algebraic perspective. To keep things as simple as possible, we are going to choose 

as a computation which lookups up what to do depending on the environment value, continuing as 
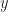
Intuitively, if we do
Here the idea is that:
- If the bit is low, we will act as the left component of the left component.
- If the bit is high, we will act as the right component of the right component.
In fact, it will turn out that these two axioms are exactly what we need. A simple consequence of the axioms is that:
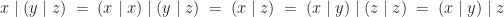
So the operation 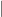

From the above equations, if we see a sequence of 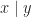

Finally, we note that

In fact, the following are equivalent for a structure over a binary operator
- The equations
and
hold.
- The equations
and
hold.
For the bottom to top direction, using associativity to ignore brackets:

Using this ability to insert arbitrary elements twice, we calculate:
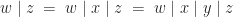
Finally, to show idempotence, reusing the first equation we proved:
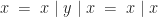
The first set of equations we derived from computational intuitions, the second set of equations identify these structures as naturally occurring algebraic objects known as rectangular bands. (A band is an associative idempotent binary operation.) So the Eilenberg-Moore category of the reader monad on a bit is the category of rectangular bands and their homomorphisms.
The State Monad
We have already encountered the state monad, as the monad induced by the Cartesian closed structure on
Explicitly, for a fixed set of states 
- Endofunctor:
.
- Unit:
.
- Multiplication:
.
Again, we are going to keep things as simple as possible, and consider a one bit state space, so 

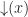
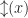
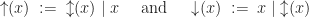
So the explicit bit setting operations are definable by only flipping the bit if it is the wrong value. Obviously, we expect that
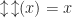
as flipping the bit twice should leave us back where we started. We also expect flipping a bit to reverse how computation proceeds:
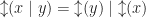
In fact, these equations give a presentation of the one bit state monad. Using the chosen equations, every term is equal to one of the form
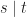
where both 


Generalising
To be more realistic, we really should consider larger state spaces or environments. Algebraically, this means instead of a binary lookup operation 
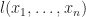
The two axioms that induce the reader monad are the obvious extensions of those for a binary bit.
You may be wondering what to do if the environment is infinite in size. There are well-defined generalisations of universal algebra where operations of these bigger arities are permitted. As long as the maximum size of the operations is bounded, this all pretty much works as in the finite case, so we shall stick with that to keep the notation clearer.
For the state monad, we also need to think about how to change the state. Generalising the bit flip operation seems unnatural, for example should we rotate through the states in some arbitrary order? A better choice is to make the update operations primitive. Without loss of generality, it is notationally convenient to fix a state space 
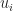
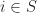



. If we don’t depend on the state, we can ignore it.
. If the state isn’t modified, we keep making the same choices.
. A second state change overwrites the first.
. Update decides a subsequent lookup.
You may have expected the first axiom to be
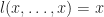
In fact, this equation is derivable using the first two. The binary case is:

The general calculation is just notationally a bit harder to read.
The equations above appear in “Notions of Computation Determine Monads” by Plotkin and Power. In fact, they consider a further generalisation, reflecting a more realistic computational setting. We now consider a situation in which we have a set of memory addresses 
If we assume each memory location can take 



. If we don’t depend on the state at an address, we can ignore it.
. If the state at an address isn’t modified, we keep making the same choices when looking up at that address.
. A second state change at the same address overwrites the first.
. Update decides a subsequent lookup at the same address.
We also require some additional axioms, which encode that the states at different addresses don’t interfere with each other.
where
. Choices based on different addresses commute with each other.
where
where
The resulting monad is the state monad on 
As usual, there are lots more details to take care of in realistic work, such as moving beyond the category

3 thoughts on “Monad bits and pieces”