In the previous post, we saw that free monads could be described in terms of initial algebras. We also saw that the free completely iterative monad could be constructed in a similar way, but using final coalgebras. That post completely skipped explaining what a completely iterative monad is, and why they are interesting. That will be the objective of the current post. Along the way, we shall encounter several familiar characters from previous posts, including ideal monads, free algebras, Eilenberg-Moore algebras and final coalgebra constructions.
Solving Equations
Solving equations is a central topic in algebra, that we deal with right from the mathematics we are taught in school. Fortunately, for this post, we shall be interested in solving more interest classes of equations than we typically encounter in those early days. For a signature 

- …
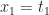

where each 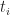

Example: Let 
.
.
These equations contain the three main components we are interested in, variables expressing unknowns 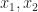
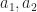
.

(Really we should bracket everything to the right, but that would hurt readability. We shall assume that all such terms implicitly bracket to the left.) Of course, these are infinite objects, and so there is no genuine term we can evaluate to define these values in this way.
In an ideal world, each such system of equations would have a unique solution. Clearly, the trivial equation 
The following example shows that we can actually consider simpler sets of guarded equations, and still retain the same expressive power.
Example: Using the same signature as the previous example, consider the following pair of equations:
.
.
The terms on the right hand side are more complex than the previous example, as they contain multiple operation symbols. By introducing further unknowns, we can describe a system of equations only using one operation in each term.
.
.
.
.
Assuming a unique solutions exists for both sets of equations, the values for 
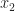
Our terms now involve only one operation symbol, and a mixture of variables and constants from
.
.
.
.
Assuming a unique solution exists for these equations, the values for 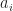
Let’s call a term flat if it contains only one operation symbol. The strategy in the previous example can be generalised to convert an arbitrary family of equations into an equivalent family involving only flat terms or constants. For a signature
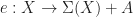
We are interested in algebras 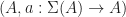

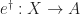
![e^{\dagger} = [a \circ \Sigma e^{\dagger}, \mathsf{id}] \circ e](https://s0.wp.com/latex.php?latex=e%5E%7B%5Cdagger%7D+%3D+%5Ba+%5Ccirc+%5CSigma+e%5E%7B%5Cdagger%7D%2C+%5Cmathsf%7Bid%7D%5D+%5Ccirc+e&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
A
Most of the algebraic objects that are encountered in ordinary mathematics are not completely iterative.
Example: For the natural numbers with addition, the system of equations:
.
.
has no solutions.
Example: For the subsets of the natural numbers, with binary unions, the system of equations:
.
.
has multiple solutions. In fact, any subset of natural numbers will do for 
We could also consider the equation 
We could thinks of both of these examples as sneakily allowing us to circumvent the restriction to guarded terms.
The free algebra over 
As we have seen last time, the free algebra at 
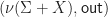

- Each internal
-ary node is labelled by an
- Each leaf is labelled by either a constant symbol, or an element of
Intuitively, the finite trees are the ordinary terms, and the infinite trees are the extra elements that allow us to solve genuinely mutually recursive systems of equations.
If we consider the full subcategory of 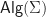


When all these final coalgebras exist, so we have a free completely iterative algebra functor, the adjunction induces a monad. This is the monad that we described as the free completely iterative monad in the previous post.
Completely Iterative Monads
We’ve now recovered the monad known as the free completely iterative monad from the previous post, via an analysis of unique solutions for certain families of mutually recursive equations. What we still haven’t done is sort out the question of exactly what a completely iterative monad is. That is the problem we turn to now. Again, solutions of mutually recursive guarded equations will be important.
We will now remove the restriction to equations involving only flat terms, and consider solutions to systems of equation involving more general terms. Abstractly such a system of equations will be encoded as a function:
Here, 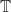


![e^{\dagger} = a \circ \mathbb([e^{\dagger}, f]) \circ e](https://s0.wp.com/latex.php?latex=e%5E%7B%5Cdagger%7D+%3D+a+%5Ccirc+%5Cmathbb%28%5Be%5E%7B%5Cdagger%7D%2C+f%5D%29+%5Ccirc+e&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
We would like unique solutions to such families of equations. As we noted previously, equations such as
We previously encountered ideal monads, which informally are monads that “keep variables separate”. These are exactly the gadget that we need in order to talk about guarded equations abstractly. We recall an ideal monad is a monad 
- There exists an endofunctor
with
.
- The unit is the left coproduct injection.
- There exists
such that
.
A system of equations 
![[\kappa_2, \eta \circ \kappa_2] : \mathbb{T}'(X + Y) + Y \rightarrow \mathbb{T}(X + Y)](https://s0.wp.com/latex.php?latex=%5B%5Ckappa_2%2C+%5Ceta+%5Ccirc+%5Ckappa_2%5D+%3A+%5Cmathbb%7BT%7D%27%28X+%2B+Y%29+%2B+Y+%5Crightarrow+%5Cmathbb%7BT%7D%28X+%2B+Y%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Finally, we are in a position to say what a completely iterative monad is!
A completely iterative monad is an ideal monad such that every guarded system of equations 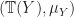
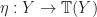
Example: Unsurprisingly, the free completely iterative monad, constructed using final coalgebras, is a completely iterative monad.
Freedom!
We’re not quite done. We claimed that the final coalgebra construction yields the free completely iterative monad. You should always be suspicious of a claim that something is a free construction, if you’re unsure about the categories and functors involved. We now pin down these details.
Firstly, we admit to being a bit naughty in a previous post. We introduced ideal monads, but didn’t specify their morphisms. We need to address that omission first.
A morphism of ideal monads:
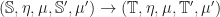
is a monad morphism 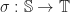

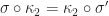
Intuitively, these a monad morphisms that don’t muddle up bare variables with guarded terms.
Let 
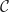
![\mathsf{CIM}(\mathcal{C}) \rightarrow [\mathcal{C}, \mathcal{C}]](https://s0.wp.com/latex.php?latex=%5Cmathsf%7BCIM%7D%28%5Cmathcal%7BC%7D%29+%5Crightarrow+%5B%5Cmathcal%7BC%7D%2C+%5Cmathcal%7BC%7D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
For an ideal monad 

A completely iterative monad 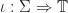


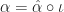
You should be a bit suspicious at this point. This doesn’t look like a normal free object definition, in particular, the restriction to ideal natural transformations is a bit odd. This is a legitimate universal property, but possibly using the term free is at odds with the usual convention, relative to the forgetful functor above. In particular, as pointed out in the original paper, the existence of all such free objects does not imply the existence of an adjoint functor. Be careful when somebody on the internet tells you something is free!
Wrapping Up
As usual, we have focussed on sets and functions, and conventionally algebraic examples as far as possible. This was for expository reasons, the theorems in this area work in much greater generality.
A good starting point for further information is “Completely Iterative Algebras and Completely Iterative Monads” by Milius. The paper has plentiful examples, and many more technical results and details than those we have sketched in this post. You will also find pointers to iterative monads and algebras in the bibliography of that paper.
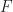 , an initial
, an initial  . Explicitly, this is an
. Explicitly, this is an  such that for every
such that for every 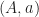 there is a unique morphism
there is a unique morphism  such that
such that
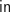 is always an isomorphism. This highlights that initial algebras generalise the notion of least fixed points for monotone maps.
is always an isomorphism. This highlights that initial algebras generalise the notion of least fixed points for monotone maps.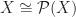 .
. , with
, with  , and:
, and: is a constant symbol in
is a constant symbol in  .
. is an
is an  then
then  .
.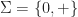 , with
, with  a constant, and
a constant, and  a binary operation. We then have:
a binary operation. We then have: .
.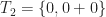 .
.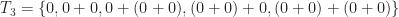 .
. for the corresponding signature functor. The algebra structure map
for the corresponding signature functor. The algebra structure map  maps the left component to the term
maps the left component to the term 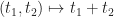
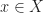 then
then  .
. then
then  for simplicity, we have:
for simplicity, we have: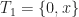 .
.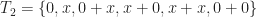 .
.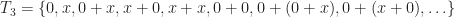 .
. , where
, where  .
. on a category with binary coproducts, if the functor
on a category with binary coproducts, if the functor  has an initial algebra, then
has an initial algebra, then 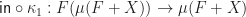 is the free
is the free 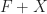 have initial algebras, the free monad on
have initial algebras, the free monad on 
 . Each of the functors
. Each of the functors 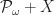 has an initial algebra. The elements of
has an initial algebra. The elements of  are the hereditarily finite sets. These are finite sets, with all elements also hereditarily finite. Similarly the elements of
are the hereditarily finite sets. These are finite sets, with all elements also hereditarily finite. Similarly the elements of 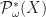 are hereditarily finite sets with atoms from
are hereditarily finite sets with atoms from  . This is the dual notion to that of an
. This is the dual notion to that of an 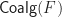 , with morphisms
, with morphisms  being
being 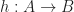 such that
such that
 is simply a function of the form
is simply a function of the form  . We could interpret this as a device, for which when we press the “go button” either jumps to a new state, ready to go again, or moves to a failure state.
. We could interpret this as a device, for which when we press the “go button” either jumps to a new state, ready to go again, or moves to a failure state. . Explicitly, this is an object
. Explicitly, this is an object  such that for every coalgebra
such that for every coalgebra  such that
such that
 yielded a monad, the free monad
yielded a monad, the free monad  . Do the objects of the form
. Do the objects of the form 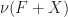 also carry the structure of a monad as well?
also carry the structure of a monad as well?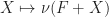 .
.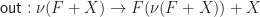 is an isomorphism. We take as our monad unit the composite
is an isomorphism. We take as our monad unit the composite  .
.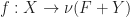 , we can define its Kleisli extension
, we can define its Kleisli extension  as the unique
as the unique  . That there is such an
. That there is such an 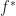 requires some more theory, that hopefully we can discuss another time. There is a more explicit description of this morphism, but unfortunately it is cumbersome to describe in this format.
requires some more theory, that hopefully we can discuss another time. There is a more explicit description of this morphism, but unfortunately it is cumbersome to describe in this format.  exists. Therefore the free completely iterative monad on
exists. Therefore the free completely iterative monad on 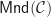 for the category of monads on a category
for the category of monads on a category ![[\mathcal{C},\mathcal{C}]](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BC%7D%2C%5Cmathcal%7BC%7D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) for the category of endofunctors on
for the category of endofunctors on ![\mathsf{Mnd}(\mathcal{C}) \rightarrow [\mathcal{C},\mathcal{C}]](https://s0.wp.com/latex.php?latex=%5Cmathsf%7BMnd%7D%28%5Cmathcal%7BC%7D%29+%5Crightarrow+%5B%5Cmathcal%7BC%7D%2C%5Cmathcal%7BC%7D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 such that for every monad
such that for every monad  there exists a unique monad morphism
there exists a unique monad morphism  such that
such that
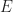 , the exception monad
, the exception monad  is the free monad over the constant endofunctor
is the free monad over the constant endofunctor  mapping everything to
mapping everything to 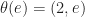
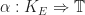 the unique fill-in morphism is:
the unique fill-in morphism is:
 , and a morphism
, and a morphism  is a
is a 
 is the full subcategory of
is the full subcategory of  consisting of the objects satisfying the unit and multiplication axioms for an Eilenberg-Moore algebra.
consisting of the objects satisfying the unit and multiplication axioms for an Eilenberg-Moore algebra. . If this functor has a left adjoint
. If this functor has a left adjoint  , then this induces a monad
, then this induces a monad  on
on 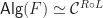
 as in the discussion above, it is referred to as the algebraically free monad over
as in the discussion above, it is referred to as the algebraically free monad over 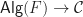 has a left adjoint, and
has a left adjoint, and  .
. . This functor is given by the follow coproduct:
. This functor is given by the follow coproduct: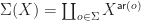
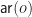 denotes the arity of operation symbol
denotes the arity of operation symbol 
 . The function
. The function  is equivalent to giving a binary function
is equivalent to giving a binary function 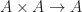 , corresponding to the binary operation symbol, and an element of
, corresponding to the binary operation symbol, and an element of 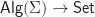 exists, and so therefore does the free monad over
exists, and so therefore does the free monad over  is the set of all terms over the signature. As usual, it is important to consider examples:
is the set of all terms over the signature. As usual, it is important to consider examples:
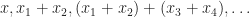
 .
. just relabels the leaves of trees, according to the function
just relabels the leaves of trees, according to the function 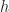 .
. can be restricted to the non-trivial trees, as these are preserved by the functor action. We shall denote this functor
can be restricted to the non-trivial trees, as these are preserved by the functor action. We shall denote this functor  .
. .
. in the sense that
in the sense that  .
.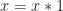 , so the unit is not a coproduct injection. Similarly, the non-ideal multiset monad restricts to the non-empty multiset monad, which is ideal.
, so the unit is not a coproduct injection. Similarly, the non-ideal multiset monad restricts to the non-empty multiset monad, which is ideal.  then ensures the monad unit cannot be a coproduct injection.
then ensures the monad unit cannot be a coproduct injection. is provable, as we have seen in the example above.
is provable, as we have seen in the example above. , there is a monad with:
, there is a monad with: .
. .
.  .
.  produces an output that depends on some state or environment it can read. Note the environment is fixed, computations cannot make modifications to it – this will be addressed later.
produces an output that depends on some state or environment it can read. Note the environment is fixed, computations cannot make modifications to it – this will be addressed later. . This has a right adjoint
. This has a right adjoint 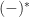 , with action on objects
, with action on objects 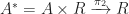 . In turn, this functor has a further right adjoint
. In turn, this functor has a further right adjoint 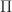 . The composite
. The composite  induces the reader monad.
induces the reader monad. 


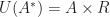 , and via Cartesian closure functions
, and via Cartesian closure functions  bijectively correspond to functions
bijectively correspond to functions  . Therefore,
. Therefore,  . (The abstract argument generalises well beyond
. (The abstract argument generalises well beyond  . So computations have access to a single binary bit of external data, which can be set low (0) or high (1). As usual, we would like to have an algebraic presentation of this monad. It is natural to introduce a binary lookup operation
. So computations have access to a single binary bit of external data, which can be set low (0) or high (1). As usual, we would like to have an algebraic presentation of this monad. It is natural to introduce a binary lookup operation  , such that informally we interpret
, such that informally we interpret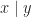
 if the bit is low, or
if the bit is low, or 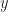 if it is high. We now need to identify some suitable equational axioms that this operation should respect. An immediate idea is to require the operation to be idempotent, that is
if it is high. We now need to identify some suitable equational axioms that this operation should respect. An immediate idea is to require the operation to be idempotent, that is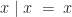

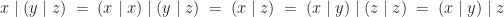
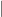 is associative. So we can now avoid the annoyance of writing brackets everywhere. We also notice that:
is associative. So we can now avoid the annoyance of writing brackets everywhere. We also notice that:
 .
.
 and
and 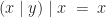 hold.
hold.
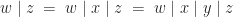
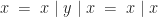
 , this monad has:
, this monad has: .
. .
. .
.  . We would like to find an equational presentation for this monad. An obvious place to start is to extend the presentation for the one bit reader monad above, which gives us the infrastructure to decide how to proceed based on the current state. A natural next step is to add operations to manipulate the bit. We could add two unary update operations, say with
. We would like to find an equational presentation for this monad. An obvious place to start is to extend the presentation for the one bit reader monad above, which gives us the infrastructure to decide how to proceed based on the current state. A natural next step is to add operations to manipulate the bit. We could add two unary update operations, say with  and
and 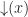 meaning set the state high (low) and proceed as
meaning set the state high (low) and proceed as 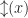 with the intuitive reading of flip the state to its opposite value, and proceed as
with the intuitive reading of flip the state to its opposite value, and proceed as 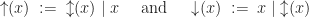
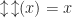
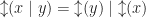
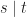
 and
and  are either a variable, or of the form
are either a variable, or of the form  .
. 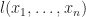
 of natural numbers. We introduce a unary operation
of natural numbers. We introduce a unary operation 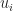 for each
for each 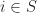 . The intuitive reading is that
. The intuitive reading is that  updates the state to
updates the state to  and continues as
and continues as  . The equations we require, with their intuitive readings are:
. The equations we require, with their intuitive readings are: . If we don’t depend on the state, we can ignore it.
. If we don’t depend on the state, we can ignore it. . If the state isn’t modified, we keep making the same choices.
. If the state isn’t modified, we keep making the same choices. . A second state change overwrites the first.
. A second state change overwrites the first. . Update decides a subsequent lookup.
. Update decides a subsequent lookup.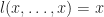

 for each
for each  , and update operations
, and update operations  , intuitively setting address
, intuitively setting address 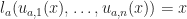 . If we don’t depend on the state at an address, we can ignore it.
. If we don’t depend on the state at an address, we can ignore it.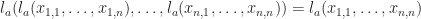 . If the state at an address isn’t modified, we keep making the same choices when looking up at that address.
. If the state at an address isn’t modified, we keep making the same choices when looking up at that address.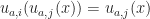 . A second state change at the same address overwrites the first.
. A second state change at the same address overwrites the first. . Update decides a subsequent lookup at the same address.
. Update decides a subsequent lookup at the same address.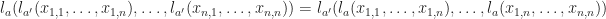 where
where  . Choices based on different addresses commute with each other.
. Choices based on different addresses commute with each other. where
where 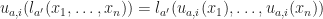 where
where  . Although the algebraic perspective on the reader and state monads was somewhat involved, this does pay off. For example, we now have the data needed to introduce algebraic operations and effect handlers for these monads.
. Although the algebraic perspective on the reader and state monads was somewhat involved, this does pay off. For example, we now have the data needed to introduce algebraic operations and effect handlers for these monads. as effectful computations over an object
as effectful computations over an object  .
. is a trivial computation that returns the value
is a trivial computation that returns the value  can be seen as a form of bounded non-determinism.
can be seen as a form of bounded non-determinism.  is a trivially non-deterministic computation that always results in the value
is a trivially non-deterministic computation that always results in the value 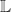 can be seen as a form of non-determinism which can be easier to implement in a programming language. It is unusual as there is an order on computations, and repeated values are allowed. Obviously another perspective is to see such computations as living in a list data structure. Again
can be seen as a form of non-determinism which can be easier to implement in a programming language. It is unusual as there is an order on computations, and repeated values are allowed. Obviously another perspective is to see such computations as living in a list data structure. Again ![\eta(x) = [x]](https://s0.wp.com/latex.php?latex=%5Ceta%28x%29+%3D+%5Bx%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) is the trivial singleton list containing only the value
is the trivial singleton list containing only the value 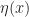 yields a trivially effectful computation in some suitable sense. To get any real use out of these computational effects, we need to be able to build less boring examples as well. To solve this problem, as usual we shall adopt an algebraic perspective. Assume we have an equational presentation
yields a trivially effectful computation in some suitable sense. To get any real use out of these computational effects, we need to be able to build less boring examples as well. To solve this problem, as usual we shall adopt an algebraic perspective. Assume we have an equational presentation  . An
. An  induces a function
induces a function  as follows:
as follows:![([t_1],\ldots,[t_n]) \mapsto [o(t_1,\ldots,t_n)]](https://s0.wp.com/latex.php?latex=%28%5Bt_1%5D%2C%5Cldots%2C%5Bt_n%5D%29+%5Cmapsto+%5Bo%28t_1%2C%5Cldots%2Ct_n%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 with action
with action 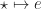 , which we can think of as raising the exception
, which we can think of as raising the exception  and a constant element
and a constant element  . The constant induces a function
. The constant induces a function 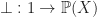 with action
with action  , which we can think of as picking out a diverging computation.
, which we can think of as picking out a diverging computation. with action
with action 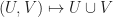 , which takes two non-deterministic computations, and combines their possible behaviours. For example
, which takes two non-deterministic computations, and combines their possible behaviours. For example  is a computation yielding either
is a computation yielding either  , and a constant element
, and a constant element  . The constant induces a function
. The constant induces a function  with action
with action ![\star \mapsto []](https://s0.wp.com/latex.php?latex=%5Cstar+%5Cmapsto+%5B%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
.  with action
with action ![([x_1,\ldots,x_m],[x_{m + 1}, \ldots, x_{n}]) \mapsto [x_1,\ldots,x_n]](https://s0.wp.com/latex.php?latex=%28%5Bx_1%2C%5Cldots%2Cx_m%5D%2C%5Bx_%7Bm+%2B+1%7D%2C+%5Cldots%2C+x_%7Bn%7D%5D%29+%5Cmapsto+%5Bx_1%2C%5Cldots%2Cx_n%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) concatentating two lists. We can interpret these operations as simply manipulating data structures, or more subtly as a form of non-determinism in which the operations respect the order on choices.
concatentating two lists. We can interpret these operations as simply manipulating data structures, or more subtly as a form of non-determinism in which the operations respect the order on choices.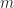 denote the set
denote the set 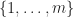 . A family of
. A family of ![([t_i])_{1 \leq i \leq m}](https://s0.wp.com/latex.php?latex=%28%5Bt_i%5D%29_%7B1+%5Cleq+i+%5Cleq+m%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) , can be identified with a morphism
, can be identified with a morphism  , and a single
, and a single 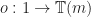 . The composite
. The composite 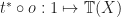 , where
, where  denotes the Kleisli extension of
denotes the Kleisli extension of  induced by Kleisli morphism to behave in a suitably uniform way. That is, they should be natural in some sense. This actually requires a modicum of care to get right. We should really consider our mapping as being of type
induced by Kleisli morphism to behave in a suitably uniform way. That is, they should be natural in some sense. This actually requires a modicum of care to get right. We should really consider our mapping as being of type 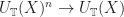 . Here,
. Here, 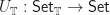 is the forgetful functor from the Kleisli category. This has action on objects
is the forgetful functor from the Kleisli category. This has action on objects 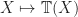 , so this rephrasing makes sense. We then note that the induced maps:
, so this rephrasing makes sense. We then note that the induced maps: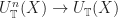
 , referred to as generic effects.
, referred to as generic effects. and
and  , so so they give us no way “out of the monad”.
, so so they give us no way “out of the monad”.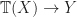 for some
for some 
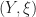 , and a homomorphism
, and a homomorphism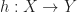

 specifies how the structure used to build up an effectful computation should be evaluated, in a manner respecting the structure encoded by the monad.
specifies how the structure used to build up an effectful computation should be evaluated, in a manner respecting the structure encoded by the monad. must act as the identity on the left component of the coproduct, and send each element of the right component to any value of its choosing in
must act as the identity on the left component of the coproduct, and send each element of the right component to any value of its choosing in 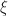 when it encounters a raised exception.
when it encounters a raised exception.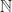 specified by taking the maximum of pairs of elements, and bottom value
specified by taking the maximum of pairs of elements, and bottom value 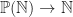 induced by the identity will map a finite set to its maximum value (inevitably defaulting to
induced by the identity will map a finite set to its maximum value (inevitably defaulting to 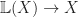 that multiplies a list of matrices together from left to right. Note that this example fundamentally exploits the fact that the multiplication operation is not forced to be commutative.
that multiplies a list of matrices together from left to right. Note that this example fundamentally exploits the fact that the multiplication operation is not forced to be commutative.![t[t_x / x \mid x \in X]](https://s0.wp.com/latex.php?latex=t%5Bt_x+%2F+x+%5Cmid+x+%5Cin+X%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
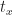 . For an equational presentation
. For an equational presentation ![([s],[t]) \in \mathbb{T}(X) \times \mathbb{T}(Y)](https://s0.wp.com/latex.php?latex=%28%5Bs%5D%2C%5Bt%5D%29+%5Cin+%5Cmathbb%7BT%7D%28X%29+%5Ctimes+%5Cmathbb%7BT%7D%28Y%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![[t]](https://s0.wp.com/latex.php?latex=%5Bt%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) denotes an equivalence class with representative term
denotes an equivalence class with representative term ![\mathsf{dst}([s],[t]) = [t[s[(x,y)/x \mid x \in X] / y \mid y \in Y]]](https://s0.wp.com/latex.php?latex=%5Cmathsf%7Bdst%7D%28%5Bs%5D%2C%5Bt%5D%29+%3D+%5Bt%5Bs%5B%28x%2Cy%29%2Fx+%5Cmid+x+%5Cin+X%5D++%2F+y+%5Cmid+y+%5Cin+Y%5D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\mathsf{dst}'([s],[t]) = [s[t[(x,y)/y \mid y \in Y] / x \mid x \in X]]](https://s0.wp.com/latex.php?latex=%5Cmathsf%7Bdst%7D%27%28%5Bs%5D%2C%5Bt%5D%29+%3D+%5Bs%5Bt%5B%28x%2Cy%29%2Fy+%5Cmid+y+%5Cin+Y%5D+%2F+x+%5Cmid+x+%5Cin+X%5D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 , the following equality is provable in equational logic:
, the following equality is provable in equational logic:![t[s[(x,y)/x \mid x \in X] / y \mid y \in Y] = s[t[(x,y)/y \mid y \in Y] / x \mid x \in X]](https://s0.wp.com/latex.php?latex=t%5Bs%5B%28x%2Cy%29%2Fx+%5Cmid+x+%5Cin+X%5D++%2F+y+%5Cmid+y+%5Cin+Y%5D+%3D+s%5Bt%5B%28x%2Cy%29%2Fy+%5Cmid+y+%5Cin+Y%5D+%2F+x+%5Cmid+x+%5Cin+X%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 and
and  be a choice of enumeration of the variables appearing in the two terms. We can then write them as
be a choice of enumeration of the variables appearing in the two terms. We can then write them as
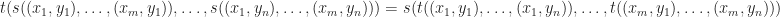
![[x + x'] \in \mathbb{T}(X)](https://s0.wp.com/latex.php?latex=%5Bx+%2B+x%27%5D+%5Cin+%5Cmathbb%7BT%7D%28X%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002) and
and ![[y \times y'] \in \mathbb{T}(Y)](https://s0.wp.com/latex.php?latex=%5By+%5Ctimes+y%27%5D+%5Cin+%5Cmathbb%7BT%7D%28Y%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002) are:
are:![\mathsf{dst}([x + x'], [y \times y']) = [((x,y) + (x',y)) \times ((x,y') + (x',y'))]](https://s0.wp.com/latex.php?latex=%5Cmathsf%7Bdst%7D%28%5Bx+%2B+x%27%5D%2C+%5By+%5Ctimes+y%27%5D%29+%3D+%5B%28%28x%2Cy%29+%2B+%28x%27%2Cy%29%29+%5Ctimes+%28%28x%2Cy%27%29+%2B+%28x%27%2Cy%27%29%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\mathsf{dst}'([x + x'], [y \times y']) = [((x,y) \times (x,y')) + ((x',y) \times (x',y'))]](https://s0.wp.com/latex.php?latex=%5Cmathsf%7Bdst%7D%27%28%5Bx+%2B+x%27%5D%2C+%5By+%5Ctimes+y%27%5D%29+%3D+%5B%28%28x%2Cy%29+%5Ctimes+%28x%2Cy%27%29%29+%2B+%28%28x%27%2Cy%29+%5Ctimes+%28x%27%2Cy%27%29%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

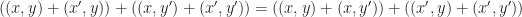
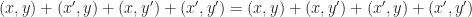

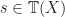 and
and 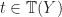 be terms in which only one variable appears, say
be terms in which only one variable appears, say 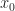 and
and 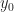 respectively. Then the left hand side of the commutativity condition is:
respectively. Then the left hand side of the commutativity condition is:![t[s[(x,y)/x \mid x \in X] / y \mid y \in Y] = t(s((x_0,y_0)))](https://s0.wp.com/latex.php?latex=t%5Bs%5B%28x%2Cy%29%2Fx+%5Cmid+x+%5Cin+X%5D++%2F+y+%5Cmid+y+%5Cin+Y%5D+%3D+t%28s%28%28x_0%2Cy_0%29%29%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![s[t[(x,y)/y \mid y \in Y] / x \mid x \in X] = s(t((x_0,y_0)))](https://s0.wp.com/latex.php?latex=s%5Bt%5B%28x%2Cy%29%2Fy+%5Cmid+y+%5Cin+Y%5D+%2F+x+%5Cmid+x+%5Cin+X%5D+%3D+s%28t%28%28x_0%2Cy_0%29%29%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 .
.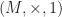 the writer monad has:
the writer monad has: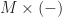 .
.  .
. .
. .
. .
. if and only if
if and only if  in the monoid.
in the monoid.![t[x_0[(x,y)/x \mid x \in X] / y \mid y \in Y] = t[(x_0,y) \mid y \in Y]](https://s0.wp.com/latex.php?latex=t%5Bx_0%5B%28x%2Cy%29%2Fx+%5Cmid+x+%5Cin+X%5D++%2F+y+%5Cmid+y+%5Cin+Y%5D+%3D+t%5B%28x_0%2Cy%29+%5Cmid+y+%5Cin+Y%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![x_0[t[(x,y)/y \mid y \in Y] / x \mid x \in X] = t[(x_0,y) \mid y \in Y]](https://s0.wp.com/latex.php?latex=x_0%5Bt%5B%28x%2Cy%29%2Fy+%5Cmid+y+%5Cin+Y%5D+%2F+x+%5Cmid+x+%5Cin+X%5D+%3D+t%5B%28x_0%2Cy%29+%5Cmid+y+%5Cin+Y%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
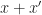 and a unary term
and a unary term ![([h],[0])](https://s0.wp.com/latex.php?latex=%28%5Bh%5D%2C%5B0%5D%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002) and
and ![([h],[x + x'])](https://s0.wp.com/latex.php?latex=%28%5Bh%5D%2C%5Bx+%2B+x%27%5D%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002) are:
are: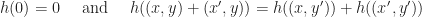

 and set
and set 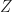 , the term
, the term  induces an
induces an  with action
with action ![(([t_{1,1}],\ldots,[t_{1,k}]),\ldots,([t_{m,1},\ldots,t_{m,k}])) \mapsto ([s(t_{1,1},\ldots,t_{m,1})],\ldots,[s(t_{1,k},\ldots,t_{m,k})])](https://s0.wp.com/latex.php?latex=%28%28%5Bt_%7B1%2C1%7D%5D%2C%5Cldots%2C%5Bt_%7B1%2Ck%7D%5D%29%2C%5Cldots%2C%28%5Bt_%7Bm%2C1%7D%2C%5Cldots%2Ct_%7Bm%2Ck%7D%5D%29%29+%5Cmapsto+%28%5Bs%28t_%7B1%2C1%7D%2C%5Cldots%2Ct_%7Bm%2C1%7D%29%5D%2C%5Cldots%2C%5Bs%28t_%7B1%2Ck%7D%2C%5Cldots%2Ct_%7Bm%2Ck%7D%29%5D%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
.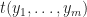 induces an
induces an 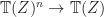 with action
with action ![([t_1],\ldots, [t_n]) \mapsto [t(t_1,\ldots,t_n)]](https://s0.wp.com/latex.php?latex=%28%5Bt_1%5D%2C%5Cldots%2C+%5Bt_n%5D%29+%5Cmapsto+%5Bt%28t_1%2C%5Cldots%2Ct_n%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
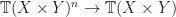 induced by
induced by  satisfying the following equations:
satisfying the following equations: ,
, 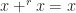 .
. .
. ,
, 
 forms the probabilistic mixture
forms the probabilistic mixture  and the axioms can be understood from this point of view. The pseudo-associativity axiom is particularly unpleasant to look at, but is easier to understand in terms of re-bracketing weighted binary combinations.
and the axioms can be understood from this point of view. The pseudo-associativity axiom is particularly unpleasant to look at, but is easier to understand in terms of re-bracketing weighted binary combinations. 
 . So there is a commutative monad presented by an algebraic theory with (many different) non-commutative algebraic operations.
. So there is a commutative monad presented by an algebraic theory with (many different) non-commutative algebraic operations. and
and  , with the only equations being those requiring both operations are commutative. We consider the action of the double strengths on the equivalence classes
, with the only equations being those requiring both operations are commutative. We consider the action of the double strengths on the equivalence classes ![[w \oplus x]](https://s0.wp.com/latex.php?latex=%5Bw+%5Coplus+x%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) and
and ![[y \otimes z]](https://s0.wp.com/latex.php?latex=%5By+%5Cotimes+z%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) . For the first:
. For the first:![\mathsf{dst}([w \oplus x], [y \otimes z]) = [((w,y)\oplus(x,y)) \otimes ((w,z)\oplus(x,z))]](https://s0.wp.com/latex.php?latex=%5Cmathsf%7Bdst%7D%28%5Bw+%5Coplus+x%5D%2C+%5By+%5Cotimes+z%5D%29+%3D+%5B%28%28w%2Cy%29%5Coplus%28x%2Cy%29%29+%5Cotimes+%28%28w%2Cz%29%5Coplus%28x%2Cz%29%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\mathsf{dst}'([w \oplus x], [y \otimes z]) = [((w,y)\otimes(w,z)) \oplus ((x,y)\otimes(x,z))]](https://s0.wp.com/latex.php?latex=%5Cmathsf%7Bdst%7D%27%28%5Bw+%5Coplus+x%5D%2C+%5By+%5Cotimes+z%5D%29+%3D+%5B%28%28w%2Cy%29%5Cotimes%28w%2Cz%29%29+%5Coplus+%28%28x%2Cy%29%5Cotimes%28x%2Cz%29%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![[((w,y)\oplus(x,y)) \otimes ((w,z)\oplus(x,z))] = [((w,y)\otimes(w,z)) \oplus ((x,y)\otimes(x,z))]](https://s0.wp.com/latex.php?latex=%5B%28%28w%2Cy%29%5Coplus%28x%2Cy%29%29+%5Cotimes+%28%28w%2Cz%29%5Coplus%28x%2Cz%29%29%5D++%3D+%5B%28%28w%2Cy%29%5Cotimes%28w%2Cz%29%29+%5Coplus+%28%28x%2Cy%29%5Cotimes%28x%2Cz%29%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
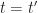 in our theory must have the same number of occurrences of
in our theory must have the same number of occurrences of 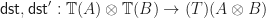
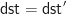 . We saw last time that the list monad is not commutative, but the powerset monad is. In this post we will restrict ourselves to examining some more instructive examples. This will help build our intuitions, and the examples lay the groundwork for discussions in later posts.
. We saw last time that the list monad is not commutative, but the powerset monad is. In this post we will restrict ourselves to examining some more instructive examples. This will help build our intuitions, and the examples lay the groundwork for discussions in later posts. .
.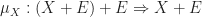 does the “obvious thing”,
does the “obvious thing”,  ,
,  and
and  .
. as a function that transforms elements of
as a function that transforms elements of  .
. .
. .
. .
. .
.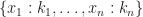
 appears with multiplicity
appears with multiplicity  . The action of both double strength maps sends the pair of multisets:
. The action of both double strength maps sends the pair of multisets:
 .
.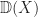 has elements finitely supported formal convex sums
has elements finitely supported formal convex sums  . These are weighted sum of elements of
. These are weighted sum of elements of  ,
,  ,
,  and only finitely many
and only finitely many ![X \rightarrow [0,1]](https://s0.wp.com/latex.php?latex=X+%5Crightarrow+%5B0%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) satisfying the previous conditions on the weights.
satisfying the previous conditions on the weights.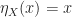 . That is, the unit maps an element of
. That is, the unit maps an element of  . This is simply flattening out a sum of sums.
. This is simply flattening out a sum of sums.


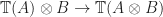
 .
.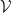 is a symmetric monoidal category we can build a costrength from a strength
is a symmetric monoidal category we can build a costrength from a strength 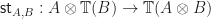
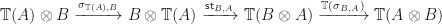
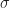 is the symmetry isomorphism from the symmetric monoidal structure. Intuitively, we just swap the inputs, use the strength and swap them back again.
is the symmetry isomorphism from the symmetric monoidal structure. Intuitively, we just swap the inputs, use the strength and swap them back again.![([a_1,\ldots,a_n],b) \mapsto [(a_1,b),\ldots,(a_n,b)]](https://s0.wp.com/latex.php?latex=%28%5Ba_1%2C%5Cldots%2Ca_n%5D%2Cb%29+%5Cmapsto+%5B%28a_1%2Cb%29%2C%5Cldots%2C%28a_n%2Cb%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

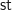 and costrength
and costrength  . In fact, there are two ways we can do this, either by applying strength first:
. In fact, there are two ways we can do this, either by applying strength first:

![\mathsf{dst}([a,b],[c,d]) = [(a,c),(b,c),(a,d),(b,d)]](https://s0.wp.com/latex.php?latex=%5Cmathsf%7Bdst%7D%28%5Ba%2Cb%5D%2C%5Bc%2Cd%5D%29+%3D+%5B%28a%2Cc%29%2C%28b%2Cc%29%2C%28a%2Cd%29%2C%28b%2Cd%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\mathsf{dst}'([a,b],[c,d]) = [(a,c),(a,d),(b,c),(b,d)]](https://s0.wp.com/latex.php?latex=%5Cmathsf%7Bdst%7D%27%28%5Ba%2Cb%5D%2C%5Bc%2Cd%5D%29+%3D+%5B%28a%2Cc%29%2C%28a%2Cd%29%2C%28b%2Cc%29%2C%28b%2Cd%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
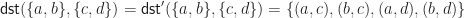
 , but the two composites may agree for some monads. This question, and its implications are another key topic in the theory of monads. We shall begin exploring the details in the next post.
, but the two composites may agree for some monads. This question, and its implications are another key topic in the theory of monads. We shall begin exploring the details in the next post. . Intuitively, this is a generalization of the notion of monoid from sets to categories. There are isomorphisms
. Intuitively, this is a generalization of the notion of monoid from sets to categories. There are isomorphisms  ,
, ,
, , encoding associativity up to isomorphism. The unitors and associator are required to satisfy some compatibility equations (referred to as coherence conditions). We won’t need the details, but they can be found in any standard category theory reference.
, encoding associativity up to isomorphism. The unitors and associator are required to satisfy some compatibility equations (referred to as coherence conditions). We won’t need the details, but they can be found in any standard category theory reference.
 . Again, the symmetry is required to satisfy some coherence conditions (equations) with respect to the other structure. Finally, a (symmetric) monoidal closed category is a (symmetric) monoidal category such that for each object
. Again, the symmetry is required to satisfy some coherence conditions (equations) with respect to the other structure. Finally, a (symmetric) monoidal closed category is a (symmetric) monoidal category such that for each object 

 given by the exponential
given by the exponential  .
. , a strength (sometimes referred to as a tensorial strength) for
, a strength (sometimes referred to as a tensorial strength) for  is a natural transformation
is a natural transformation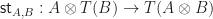
![(a, [b_1,\ldots,b_n]) \mapsto [(a,b_1),\ldots,(a,b_n)]](https://s0.wp.com/latex.php?latex=%28a%2C+%5Bb_1%2C%5Cldots%2Cb_n%5D%29+%5Cmapsto+%5B%28a%2Cb_1%29%2C%5Cldots%2C%28a%2Cb_n%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
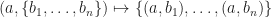
 carry additional mathematical structure, and this structure interacts well with composition. For example:
carry additional mathematical structure, and this structure interacts well with composition. For example: of preorders and monotone maps actually carry a natural pointwise order:
of preorders and monotone maps actually carry a natural pointwise order:  .
. 

 are themselves categories, with morphisms the natural transformations. Furthermore, the composition maps are bifunctors
are themselves categories, with morphisms the natural transformations. Furthermore, the composition maps are bifunctors

 can be given the structure of Abelian groups pointwise. With this structure, the composition maps satisfy:
can be given the structure of Abelian groups pointwise. With this structure, the composition maps satisfy: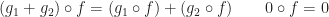
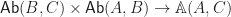
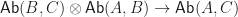

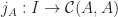 . Intuitively, these encode the the identities in the category.
. Intuitively, these encode the the identities in the category. , a morphism
, a morphism  . These encode composition of morphisms with the enriched category.
. These encode composition of morphisms with the enriched category.
 , with the same objects, and homsets:
, with the same objects, and homsets:
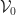 are defined in a natural way. Strictly speaking, to give an enrichment for an ordinary category
are defined in a natural way. Strictly speaking, to give an enrichment for an ordinary category  , and a specified isomorphism
, and a specified isomorphism 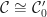 . Generally, this isomorphism is ignored when there is a natural choice.
. Generally, this isomorphism is ignored when there is a natural choice. consists of:
consists of: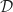 -objects.
-objects. . Intuitively, these describe the action on morphisms of the functor.
. Intuitively, these describe the action on morphisms of the functor.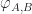 are required to satisfy axioms generalizing the usual idea that identities and composition are preserved.
are required to satisfy axioms generalizing the usual idea that identities and composition are preserved.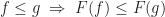 .
.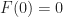 and
and  .
.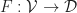 induces an ordinary functor
induces an ordinary functor  that agrees with
that agrees with  in
in 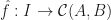 . Then
. Then  is given by:
is given by: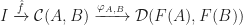 .
.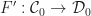 if
if 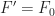 .
. is a family of
is a family of  satisfying an axiom generalizing the usual notion of naturality to the enriched setting.
satisfying an axiom generalizing the usual notion of naturality to the enriched setting. an ordinary endofunctor, giving a strength for
an ordinary endofunctor, giving a strength for 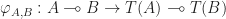

 is the counit of the adjunction, which can be seen as an evaluation morphism for function spaces. Taking the transpose of this morphism gives a map:
is the counit of the adjunction, which can be seen as an evaluation morphism for function spaces. Taking the transpose of this morphism gives a map:
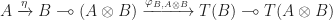
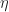 is the unit of the adjunction. Taking the transpose of this morphism gives a map:
is the unit of the adjunction. Taking the transpose of this morphism gives a map:

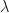 notion to define a simple function. The strengths given for the list and powerset monads in the earlier example arise via this construction.
notion to define a simple function. The strengths given for the list and powerset monads in the earlier example arise via this construction.  , the unique strength is given on representatives by:
, the unique strength is given on representatives by:![\mathsf{st}_{A,B}(a, [t]) = [t[(a,b) / b \mid b \in \mathsf{var}(t)]]](https://s0.wp.com/latex.php?latex=%5Cmathsf%7Bst%7D_%7BA%2CB%7D%28a%2C+%5Bt%5D%29+%3D+%5Bt%5B%28a%2Cb%29+%2F+b+%5Cmid+b+%5Cin+%5Cmathsf%7Bvar%7D%28t%29%5D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 is the set of variables appearing in the representative term
is the set of variables appearing in the representative term 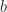 appearing in the representative term
appearing in the representative term 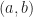 .
.