Now we have seen monads on 2-categories and bicategories, we are in a position to introduce some new ideas.
We have encountered various notions of monads so far, including:
- Idempotent monads
- Strong monads and enriched monads
- Commutative monads
- Ideal monads
- Completely iterative monads
- Free monads
These are all special cases of monads in a bicategory. This time, we are going to see a genuine generalisation. To do so, we follow a well-worn categorical trail, and adopt a functorial perspective on a familiar object, the monads themselves. This will give us yet another way of describing monads, and a suitable starting point for generalisation. The resulting graded monads are a powerful tool for modelling resource usage in a monadic setting.
A 2-Functorial Perspective
In ordinary category theory, we often consider the points in a category as morphisms from the terminal object. For example, in 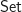


To think about the points of a 2-category, we need to introduce 2-functors. A strict 2-functor 
- A map on 0-cells,
.
- A map on 1-cells,
.
- A map on 2-cells,
.
These maps preserve identities

and composition

in the obvious way.
Put another way, a strict 2-category is simply a 
The terminal 2-category 
- A 0-cell
.
- An identity 1-cell
.
- An identity 2-cell
.
With these definitions in place, we can consider the (strict) points of a 2-category 
Such a functor can map 
As we learned last time, it is mathematically natural to relax the strict setting to one where structure is only preserved up to isomorphism. To do so, we consider strong 2-functors (often called pseudofunctors or simply 2-functors). These have the same mappings as before, but now we have isomorphism 2-cells:
.
.
As usual, these isomorphisms must satisfy some coherence equations, ensuring they are suitably compatible with each other. We will skip spelling these out explicitly.
Now consider strong 2-functors 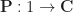
- A 0-cell
.
- A 1-cell
.
- An isomorphism 2-cell
.
- An isomorphism 2-cell
.
Possibly this is starting to look slightly familiar. A good choice of notation will hopefully clarify things further. Lets write

and name the two invertible 2-cells 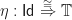

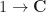
- A 0-cell
.
- A 1-cell
.
- An isomorphism 2-cell
- An isomorphism 2-cell
This looks suspiciously like the definition of a monad on the 0-cell 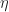

There is one remaining oddity to address, that
.
.
Notice that now these 2-cells are not required to be invertible, their direction matters. We could equally consider oplax 2-functors, in which these 2-cells go in the other direction. The lax setting is the right one for our needs. We can make the standard observation:
A monad is the same thing as a lax 2-functor from the terminal category.
We have concentrated on strict 2-categories to avoid bookkeeping yet more isomorphisms, but this observation remains true if we move to the bicategorical setting.
Time to Generalise
The point of moving to a functorial perspective is that we have a natural launching point for generalisation. We identified monads in the 2-category
As a first step, we adjust our perspective on the terminal category slightly. Any monoid can be seen as a 1-object category, with morphisms corresponding to elements of the monoid, and composition and identities given by the monoid multiplication and unit respectively. Given any category
- Consider the terminal monoid. This is the monoid with just a unit element.
- View this as an ordinary category.
- View the resulting category as a 2-category.
Obviously, we could perform these simple changes of perspective with any monoid 

- A family of 1-cells
, indexed by the elements of
- A unit 2-cell
.
- Multiplication 2-cells
.
These satisfy some generalisations of the unit and multiplication axioms, compatible with the monoid indexing.
Example: We can consider functors 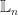


sending each element of 
![[x]](https://s0.wp.com/latex.php?latex=%5Bx%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

given by concatenation. For example:
![[[1,2],[3,4],[5,6]] \mapsto [1,2,3,4,5,6]](https://s0.wp.com/latex.php?latex=%5B%5B1%2C2%5D%2C%5B3%2C4%5D%2C%5B5%2C6%5D%5D+%5Cmapsto+%5B1%2C2%2C3%2C4%2C5%2C6%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Together, this data constitutes a graded monad, graded by the natural numbers under multiplication 
This example gives a general sense of the nature of graded monads, particularly in computer science. The grading allows us to track some quantitative data, allowing to model resources appropriate to the effects in our application. We mention another perhaps slightly surprising degenerate example:
Example: Every 1-cell 
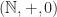
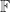

So in particular, 
The exact list example is a bit inflexible, as list lengths are fixed completely. To loosen this up, we introduce a new mathematical object. A preordered monoid is a monoid 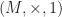
Example: The natural numbers under multiplication form a partially ordered monoid under the usual ordering on natural numbers, as:

Similarly to ordinary monoids, preordered monoid can be viewed as (thin) 2-categories, with 2-cells between 1-cells 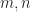


Example: There is a second family of list functors 
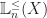
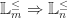
promoting lists of shorter length to the longer context. These constitute a 
We can go further, and in the extreme consider monads graded by any 2-category we like.
Conclusion
Graded monads can be seen as a resource aware generalisation of monads, with natural applications in areas such as computer science. For example, there are non-trivial graded state, writer and maybe monads. There is a lot more to explore here, for example:
- Developing the mathematics further, for example suitable Kleisli and Eilenberg-Moore constructions.
- Discussing applications of graded monads.
As ordinary monads are already a rich topic, unsurprisingly this is more than we can hope to cover properly in a single post. We may return to this subject again later.
This post owes a great deal to exposition in papers and talk slides by Tarmo Uustalu. I would recommended the slides from “Grading monads, comonads, distributive laws” as a good starting point for further reading.
Acknowledgements: Thanks to Ralph Sarkis for picking up a confusing typo in one of the examples.
